
Normalisation vs. Standardisation: Which One Should You Use?
Understand the key differences, use cases, and practical tips for applying normalization and standardization in your data preprocessing work

Introduction

When working with machine learning models, preprocessing your data is not just recommended, it’s essential. Among the most discussed preprocessing techniques are normalisation and standardisation.
While both aim to scale numerical data, they serve different purposes and are suited for different scenarios. So, which one should you use and when?
What is normalisation?
It transforms the features/variables into a fixed range, typically between [0, 1]. It is also known as min-max scaling. It uses the formula:
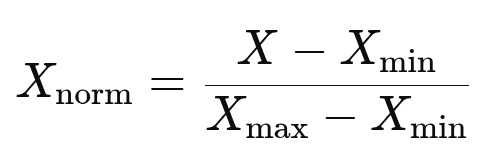
The above formula ensures that the values lie within the same scale, which is particularly useful for the following scenarios:
When the data doesn’t follow the Gaussian distribution.
When the features have different units (e.g., height in cm, weight in kg)
When you’re using distance-based algorithms like KNN or K-Means.
Example—Let us normalise this array. [10, 20, 30, 40].
min = 10, max = 40
Normalized values = [(x - 10)/(40 - 10)]
= [0.0, 0.33, 0.66, 1.0]What is standardisation?
Standardisation is also known as Z-score normalisation. It transforms the data to have a mean of 0 and a standard deviation of 1. The formula is
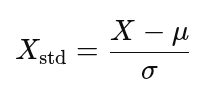
μ represents the mean.
σ represents the standard deviation.
Standardisation is ideally used when:
The data follows a normal (Gaussian) distribution
You’re using models that assume a centered distribution, like Logistic Regression, SVM, or linear regression.
Example—Take the same array. [10, 20, 30, 40]
Mean = 25, Std Dev ≈ 11.18
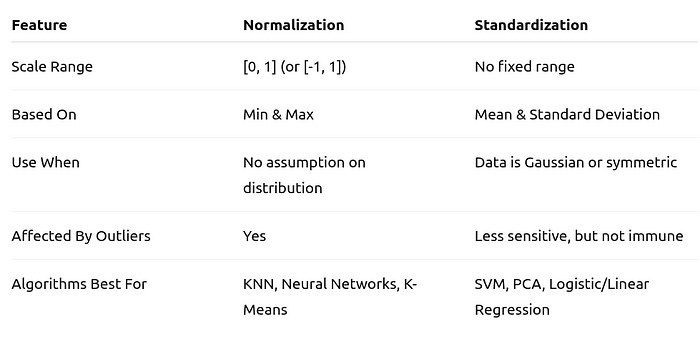
Standardized values ≈ [-1.34, -0.45, 0.45, 1.34]Key Differences at a Glance
When will things go wrong?
Consider you’re clustering customers’ income data that ranges from $20k to $2M. If you normalise, a $25k customer and a $1.5M customer may end up much closer than they should be in distance-based models due to squishing. While standardisation, in contrast, will better maintain relative differences.
Real-World Python Example
from sklearn.preprocessing import MinMaxScaler, StandardScaler
import numpy as np
data = np.array([[10], [20], [30], [40]])
# Normalization
norm = MinMaxScaler()
print("Normalized:", norm.fit_transform(data).flatten())
# Standardization
std = StandardScaler()
print("Standardized:", std.fit_transform(data).flatten())Output
Normalized: [0. 0.33 0.66 1. ]
Standardized: [-1.34 -0.45 0.45 1.34]When to use what?
Choose Normalisation when:
Your data doesn’t follow a normal distribution
You’re using algorithms based on distance metrics
You need values bounded within a range (e.g., neural networks)
Choose standardisation when:
Your model assumes a Gaussian distribution
You’re using parametric algorithms
You want to retain outlier-driven variance
Wrapping it up
Both normalisation and standardisation are often treated as interchangeable, but choosing the right one can dramatically impact your model’s performance.
💡 Quick tip: If you’re unsure about your data distribution or algorithmic requirements, try both approaches and compare results through cross-validation. Sometimes, the best answer lies in experimentation.
Connect with the author here:
LinkedIn | YouTube | Threads | Twitter | Instagram | Facebook